ArgoCD Multi-Cluster Architecture: Centralized vs Per-Cluster
By Eyal Dulberg, CTO
Installing ArgoCD on your first cluster is straightforward - we cover it in How to Set Up ArgoCD on Kubernetes. The second cluster is where architecture decisions start. Do you point your existing ArgoCD at the new cluster, or install a separate instance?
This is part of our three-part ArgoCD series. For production patterns that apply regardless of architecture, see ArgoCD in Production: Patterns That Actually Matter.
This is the ArgoCD decision that's hardest to reverse. Migrating between architectures means redefining how every application is managed, where credentials live, and how your team operates. Choose well upfront and you avoid a painful rearchitecture later.
TL;DR: There are three ArgoCD multi-cluster deployment models - centralized (hub-spoke), per-cluster (standalone), and agent-based (emerging). Centralized gives you a single dashboard but creates security and blast radius risks; per-cluster isolates failures at the cost of operational overhead; the agent model isn't production-ready yet. An orchestration layer above ArgoCD tips the scales toward per-cluster - it solves the management gaps while preserving isolation.
The Three Deployment Models
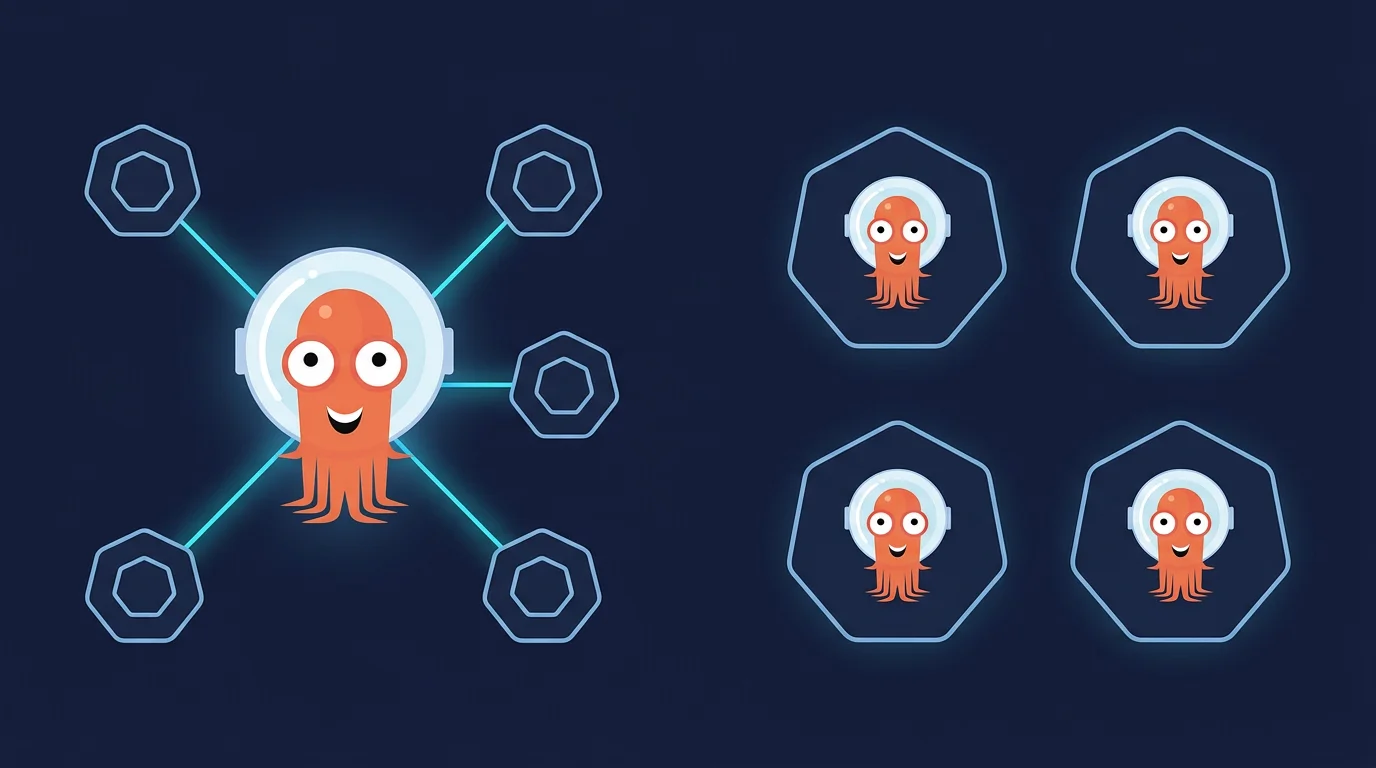
Centralized (Hub-Spoke)
One ArgoCD instance runs in a management cluster and manages deployments across your fleet. ArgoCD connects to each cluster's API server using credentials stored as Kubernetes Secrets in the argocd namespace. It polls Git, renders manifests, and pushes desired state to each cluster over the network.
What's good:
- One dashboard for sync status across all clusters
- RBAC, SSO, and notifications configured once
- ApplicationSets expand natively across all managed clusters
- Less operational overhead with few clusters
What breaks:
- Security surface grows with every cluster. The management cluster stores kubeconfigs or bearer tokens for your entire fleet. Compromise it and an attacker gets credentials to everything.
- Blast radius is total. A bad ArgoCD upgrade, misconfiguration, or OOM kill on the management cluster affects every cluster simultaneously.
- Network dependency on every cluster. ArgoCD needs persistent access to every cluster's API server. Cross-region, cross-cloud, VPN tunnels, NAT traversal - the networking complexity compounds.
- Resource pressure scales linearly. The application controller caches resource state for every managed cluster. At 15-20+ clusters, memory and CPU grow significantly even with controller sharding enabled.
A visibility tool like Radar can give you a fleet-wide dashboard without the centralized credential footprint - each cluster runs Radar locally and reports upstream over an outbound-only tunnel.
Per-Cluster (Standalone)
Each cluster runs its own ArgoCD instance that manages only the local cluster. Each instance watches Git and syncs to its own cluster. No cross-cluster credentials, no cross-cluster networking.
What's good:
- Credentials stay local. A compromised cluster doesn't hand over access to every other cluster.
- Failures are contained. A bad ArgoCD upgrade on Cluster A doesn't touch Cluster B.
- No cross-cluster network requirements. ArgoCD needs to reach Git and its own API server - that's it.
- Independent lifecycle. Teams can upgrade, test, and roll back ArgoCD per cluster on their own schedule.
What's harder:
- No unified view. You have N dashboards instead of one. Checking sync status across clusters means N browser tabs.
- Configuration drift. RBAC, SSO, notification configs need replication across instances. Without automation, they drift.
- Operational overhead. N instances to monitor, patch, upgrade, and troubleshoot.
- Cross-cluster coordination. ApplicationSets only see their local cluster. Deploying the same app across clusters requires coordinating at the Git level, not the ArgoCD level.
Agent-Based (Emerging)
A lightweight agent on each cluster communicates back to a central control plane. Unlike hub-spoke, the control plane doesn't store cluster credentials or connect to cluster API servers. The agent pulls work and applies it locally. Connections are outbound from the workload cluster, not inbound - the control plane never reaches into cluster API servers directly.
What it promises:
- Single pane of glass without the security surface of centralized
- Resource-heavy work (rendering, reconciliation) runs on the workload cluster
- Outbound-only connections from agents work through firewalls without special configuration
Where it stands today:
- Technology preview in Red Hat OpenShift GitOps 1.19+
- Not yet part of core ArgoCD OSS
- Feature parity with standard ArgoCD still catching up
- Limited production battle-testing
The agent model is where multi-cluster ArgoCD is headed long-term. For teams making architecture decisions today, it's one to watch rather than depend on.
What Actually Drives the Decision
Five factors matter more than cluster count:
| Factor | Favors Centralized | Favors Per-Cluster |
|---|---|---|
| Security posture | Trusted network, low compliance bar | Multi-tenant, regulated, zero-trust |
| Blast radius tolerance | Can absorb coordinated downtime | Prod must be isolated from dev/staging |
| Cluster count | 2-3 clusters | 5+ (especially 10+) |
| Team structure | Single platform team | Multiple teams with cluster ownership |
| Network topology | Same VPC/region, simple routing | Cross-region, cross-cloud, air-gapped |
Security and blast radius matter more than cluster count. Three clusters in a regulated environment should probably be per-cluster. Ten clusters in a single-team dev shop might still work centralized.
The common advice is "start centralized under 5 clusters, switch to per-cluster at 10+." That's fine as a starting point, but it oversimplifies. The real question is whether you can accept the security and blast radius tradeoffs of centralized - and whether you have a plan for migrating when you can't.
Why an Orchestration Layer Tips the Scales
Here's an observation that shifts the decision: per-cluster's downsides are management problems, not architectural problems.
"No unified view" means there's nothing above ArgoCD aggregating status. "Configuration drift" means there's nothing generating consistent ArgoCD configs. "Operational overhead" means there's nothing managing ArgoCD's lifecycle across clusters.
The core argument for centralized is really an argument for having a management layer. Running one ArgoCD instance happens to be the simplest way to get one - until you hit the security and scaling walls.
An orchestration layer above ArgoCD - something that manages visibility, configuration, and lifecycle across instances - changes the tradeoff matrix (we explore what this layer looks like in practice in ArgoCD in Production: Patterns That Actually Matter):
| Per-Cluster Downside | What an Orchestration Layer Provides |
|---|---|
| No unified dashboard | Cross-cluster visibility in one place |
| Config drift between instances | Configuration generated centrally, applied per-cluster |
| N instances to upgrade | Lifecycle management across the fleet |
| No cross-cluster ApplicationSets | Deployment coordination at a higher level than ArgoCD |
With this layer in place, per-cluster gives you genuine architectural benefits - credential isolation, blast radius containment, independent failure domains - without the operational tax that pushes teams toward centralized by default.
This is why we lean toward per-cluster for most teams, even those with only a few clusters. The isolation benefits are real from day one. The operational downsides are solvable with tooling. And starting centralized means signing up for a migration you'd rather avoid when you eventually outgrow it.
You can build this orchestration layer yourself - plenty of teams have. It's months of work to get right and it evolves with your infrastructure. Or you can use an existing platform. Either way, the architectural decision should be based on the properties you want (isolation vs simplicity), not on which model happens to be easier to manage without additional tooling.
Our Recommendation
Default to per-cluster. The security isolation and blast radius containment are architectural benefits you get immediately. The operational overhead is real but solvable with tooling above ArgoCD - and much easier to solve than migrating away from centralized later.
Centralized still makes sense for 2-3 clusters in a single network with one team and no compliance requirements. Just plan for the migration. Teams rarely stay at 2-3 clusters.
Watch the agent model. If you need a single pane of glass and don't have an orchestration layer, the agent approach is the most promising path to getting centralized visibility without the security tradeoffs. Give it another year or two of production hardening.
For the production patterns that apply regardless of which architecture you choose - Kustomize overlays for multi-cluster YAML, ApplicationSet generators, deletion protection, sync waves, and developer self-service - read ArgoCD in Production: Patterns That Actually Matter.
Skyhook deploys ArgoCD per-cluster by default and provides the orchestration layer on top - unified visibility, generated configuration, and managed lifecycle across your fleet. The patterns in this series describe what it automates.
Frequently Asked Questions
How many clusters can one ArgoCD instance manage?
There's no hard limit, but practically the application controller becomes resource-constrained around 15-20 clusters. ArgoCD caches the resource state for every managed cluster in memory. You can extend this with controller sharding - splitting clusters across multiple controller replicas - but the security and blast radius concerns of centralized don't go away with sharding.
Can I migrate from centralized to per-cluster ArgoCD?
Yes, but it's painful. You need to install ArgoCD on each cluster, recreate every Application resource locally, migrate credentials and RBAC, update your Git repo structure, and cut over - all without downtime. The migration typically takes weeks for production setups. This is why we recommend starting per-cluster: it's easier to add an orchestration layer on top than to decompose a centralized instance later.
What is ArgoCD agent mode?
ArgoCD agent mode is an emerging architecture where a lightweight agent runs on each workload cluster and communicates outbound to a central control plane. Unlike centralized ArgoCD, the control plane never stores cluster credentials or connects to cluster API servers directly. It's currently a technology preview in Red Hat OpenShift GitOps 1.19+ and not yet part of core ArgoCD OSS.
Should I use ArgoCD or Flux for multi-cluster?
Both are CNCF-graduated GitOps tools. ArgoCD has a built-in UI, ApplicationSets for multi-cluster templating, and a larger ecosystem. Flux is lighter-weight, uses native Kubernetes primitives (no custom UI), and has built-in multi-tenancy via Flux's Kustomization CRD. For multi-cluster specifically, ArgoCD's ApplicationSet generators make cross-cluster templating easier, while Flux relies more on Git structure and Kustomize. We cover ArgoCD here because it's what most teams adopt, but Flux is a solid choice - especially for teams that prefer a more Kubernetes-native approach.
Further Reading
- How to Set Up ArgoCD on Kubernetes - Step-by-step installation guide, from zero to your first synced application
- ArgoCD in Production: Patterns That Actually Matter - Production patterns for deletion protection, sync waves, and developer self-service
- Managing Kubernetes Add-ons: Argo CD or Terraform? - When to use each tool for different lifecycle stages
- ArgoCD Agent Architecture - Technical deep dive into the agent-based model
- ArgoCD Cluster Management - Official docs for managing external clusters